Optimization Research
Now that I’ve cleaned up the testing and documentation of MindsEye, I have been able to re-focus on why I started writing it: Optimization Algorithm Research. In the course of playing with this code I have tried countless ideas, most of which taught me though failure instead of success… However I do have two ideas, fully implemented and demonstrated in MindsEye, that I’d like to introduce today: Recursive Subspace Optimization allows deep networks to be trained effectively, and Quadratic Quasi-Newton enhances L-BFGS with a quadratic term on the line-search path.
Recursive Subspace Optimization
One common problem in network training is an “imbalanced network”. This easily happens in deep architectures when one layer has somewhat small weights, and the next layer has comparatively large weights, or visa versa. This causes the learning gradient to have a much higher magnitude in certain layers than in others, making convergence difficult since some layers have difficulty learning. Such a network could theoretically be re-balanced by re-scaling each layer; for example, the weights in one layer could be halved, and the weights in the next layer doubled, and the net effect cancels out. The network behaves the same, but has different gradients and may learn faster.
In most state-of-the-art networks, the balancing problem is solved by normalization meta-layers, which rescales each inter-layer signal so it has unit energy. By rescaling into a predetermined result, two effects are gained. Gradient magnitudes per-layer will be normalized, and back-propagation will no longer simply try to amplify signal magnitudes. (By “signal” I mean the multidimensional data output by a layer)
However, what if we chose different rates for each layer in such a way as to re-balance the learning, without needing to modify the network? Learning should then work fine, but we still have the problem of choosing these weights…
Inside a single gradient descent optimization iteration, we compute a very-high-dimensional gradient, one dimension for each weight. Normally, we would take this gradient and perform steepest descent with some rate parameter and/or line search strategy. However, in recognizing this layer-balancing issue, we could rescale this gradient by a per-layer factor to determine the next iteration’s point. If we have N layers, we now have a choice of N parameters to take the next step (via re-weighting). We of course want to pick the optimal vector, so why not define this as a gradient descent optimization problem as well?
This turned out to be fairly easy to implement in MindsEye, and it seems to work quite well. The multiple iterations spent inside the inner optimization mostly replace the line search iterations which would have taken place, and by decoupling the per-layer learning rates it can easily handle gradients many orders of magnitude dissimilar.
A similar method was published this year in Europe, but their version uses an explicitly computed Hessian, a spherical trust region, and a rigid 2-phase structure. The method I implemented shares the per-layer-rate, multi-phase-subspace optimization idea, but uses the same kind of optimization model in both phases, both of which are first-order. Theoretically, the method I propose could recurse into three or more phases, although I can’t think of a use for that right now…
Quadratic Quasi-Newton Optimization
Another feature I want to introduce today is something I am calling Quadratic Quasi-Newton optimization. This method seeks a hybrid solution with the strengths of both Stochastic Gradient Descent and Quasi-Newton (e.g. L-BFGS) approaches by defining a quadratic path for the line search phase.
Stochastic Gradient Descent (with momentum and regularization) is arguably the most common strategy used today in training deep models against big data. This method exploits only the direct differential information made available by a single evaluation over a partial sample of the data - an approximate vector of steepest descent. This leaves the choice of rate, a.k.a. step size, unspecified. In contrast, Quasi-Newton strategies predict a full optimum-point prediction on each iteration; not just a vector but also the distance. Each update uses an estimate of the second derivatives to form a quadratic functional neighborhood, which prescribes a single point at the minimum (including distance.)
While quasi-newton strategies may seem “smarter” and therefore “better”, in practice they suffer from some significant problems:
- 2nd-order derivative estimates are very sensitive to the assumption that the function is smooth and deterministic - any re-sampling of the data will invalidate the history of the known gradient rays, and numeric resolution issues can interfere with training.
- In regions of high nonlinearity, which is fairly common, the strategy may suggest a step resulting in a fitness decrease. This is why the L-BFGS strategy prescribes the Armijo & Wolfe line search conditions to guarantee convergence - in the event of a “bad” step, just try a smaller step. As long as the vector is in the direction of gradient descent vector, we are guaranteed to find an “ok” step even if it is very small.
- The estimation of the inverse hessian is a nontrivial operation. Various strategies balance memory, CPU, and accuracy, but the cost can still be significant. This also adds complexity and additional metaparameters.
- At a sufficiently small step size, not only are the extra compute resources going to waste, but we pretty much know that the direction we are choosing is not optimal because it is at an angle with the known steepest descent vector.
In either case, the method predicts what direction the solution lies in, and in either case the step size is held variable subject to some conditions to guarantee at least eventual convergence to a local optimum. Effectively, this means we can break down the optimization problem into two components that operate each iteration: The first component evaluates the differential module at the start of each iteration and produces a path through parameter space, leaving us with a one-dimensional function (with a known derivative) for us to optimize. The second uses this path to find the next iteration’s location in parameter space via an iterative “line search” procedure.
Our suggested improvement, implemented in a simple module in MindsEye, is to use a quadratic curve as the path used in the line search stage of the optimization process. This quadratic curve would be defined by intersecting the current position and gradient and the QN-predicted optimal point; the path would align with the steepest descent vector at the current point and curve smoothly through the predicted minimum. This parametric model is then fed to our line search procedure, which solves for an accepted step size. At a very small step size, this method agrees with gradient descent, but smoothly changes to account for second-order curvature effects so that a step size of 1 is exactly the QN-predicted optimum.
Results
We tested these methods by training a 3-layer convolutional network against the MNIST dataset. This problem is simple enough to run quickly, and complex enough to present a learning challenge. We used two network variants; one variant has normalization layers and the other does not, and both are initialized with a constant weight magnitude. The optimization setups tested are:
- L-BFGS with normalized network
- L-BFGS with non-normalized network
- Modified L-BFGS, with normalized network, using strong line search
- Recursive Subspace with non-normalized network, using L-BFGS as the inner optimizer.
- Quadratic Quasi-Newton with normalized network
- Recursive Subspace with non-normalized network, using QQN as the inner optimizer.
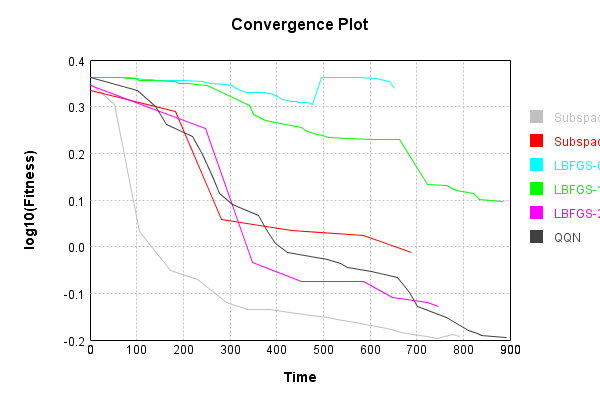
Initial results show significant benefits over standard L-BFGS, though much of the difference seen is accounted for by simply adding a strong line search to the standard L-BFGS algorithm. Over time as the test suite is expanded I should have much better data across many problems and variants to compare. Stay tuned for more!