Almost two years ago I developed a neural network library called MindsEye, which has largely sat idle since the release of TensorFlow. Recently however I’ve wanted to follow up on research involving neural networks, but I wanted a “pure” java option I could use for research. And so I decided it was time to revive my old project.
In this release, I have reviewed all of the code and made many improvements.
Good morning fellow code monkeys! Today I’d like to talk about computer vision, and how it can be used in a fairly basic fashion to process whiteboard images and improve them.
This technology is fairly mainstream, but the reader should be warned that Microsoft holds a patent on rectifying whiteboard images, but I doubt it would stand up in court. There are also many other patents that seem similar. As always, make your millions at your own risk.
Text classification is a common machine learning task which is known in various contexts as sentiment analysis, language detection, and category tagging. Many standard AI tools can be used on text given an appropriate feature selection function, which essentially transforms text down into a high-dimensional vector. However there are also certain techniques that work directly on the text, and this article is about a couple of those techniques that are enabled and demonstrated by the new release of the CharTrie component of the SimiaCryptus utilities library.
The recent wave of publishing and releases included a particularly interesting text analysis component that I’d like to talk about today. There are many possible uses, including text classification, clustering, compression, and creation. Most people would most likely recognize this as the data structure behind Markov strings or full text indexes.
This new component is logically a Trie Map that counts n-grams. The idea is that we can break text down into a number of overlapping n-grams, ie N-character strings like the 4-grams “frog” or “n th”.
Over the past several years I’ve practiced self-publishing my research projects, both by public GitHub archives and via articles on this blog. Doing so required very little effort, and it was important to me that my research be accessible. An interested reader could easily clone and build any of the projects I have discussed in previous articles, and that was good enough.
I have now taken the next step in self-publishing open source software: I have configured maven deployment to the central maven repository, and have also configured and published sites for each module using GitHub Pages.
I discussed in my previous blog post a distributed software transactional memory library I was implementing in Scala. Being a platform, it is hard to demonstrate without some interesting application running on it. I have thus created a decision tree service - a RESTful api to populate, train, and query decision tree structures.
As the majority of this post will discuss the decision tree service, I would like to emphasize that this is merely a demo application for a research-grade platform.
In today’s article, i am excited to announce the release of my new project, reSTM. The idea is to implement a database layer based on software transactional memory, allowing client-side business logic to operate generically against a database with transactional guarantees. Additionally, the memory access protocol is designed as a JSON REST service, encouraging transparency and interoperability. I believe this approach can fill an under-addressed need in modern software technologies, with its scalable NoSQL approach to transactional data.
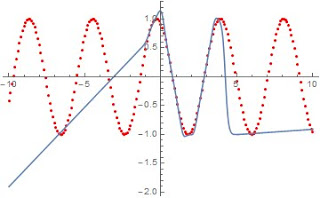
Normally, when performing regression to fit an analytical function to data, there are only a couple standard “textbook” methods to follow. The first is a least-squares fit, usually solved via gradient descent or matrix methods. The other is single-class SVM. This article will discuss a variant on the least-squares method by exploring different loss functions and the resulting behavior.
Let us begin by identifying function candidates. I find it useful to think of these functions as potential wells; it provides a good physical intuition and my descriptions will reflect this viewpoint.
Blurred Image
Deblurred Image
Recently, Google open-sourced a toolkit called TensorFlow which provides a platform for neural networks. It provides a native core written in C, and many examples written in Python. Although the architecture is extensible and will hopefully will be usable from Java/Scala application code in the future, I took some time recently to evaluate it using Python to perform deconvolutions (a.k.a. deblurring), the same task I recently wrote about using my own NN library.
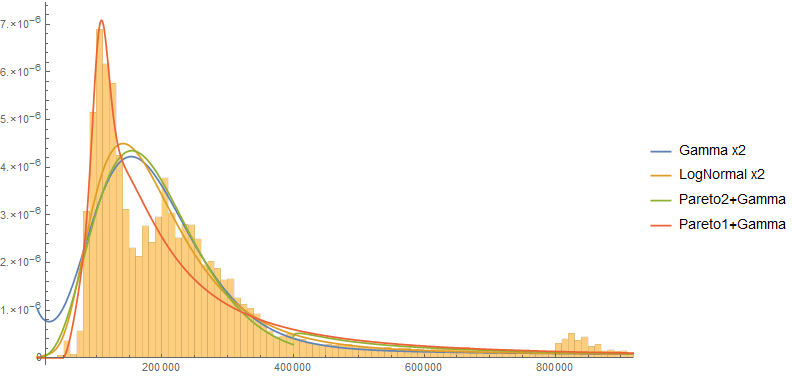
Website request latencies, as a dataset, are odd. I can think of no other dataset I have encountered so frequently in my work, but when you do research about this dataset online, you find amazingly little compared to similar topics. Therefore, let’s talk about this today - specifically, what does the ideal statistical model for website latency look like?
The background for statistical modeling is large, and it is covered in several different approaches.