Deep Learning has in recent years seen dramatic success in the field of computer vision. Deep convolutional neural networks tens of layers deep are becoming common and are some of the best performers for image recognition. Additionally, these learned networks can be used to produce novel artwork, as seen in recent publications about Deep Dream and Style Transfer. Today we will explore these applications with our own neural network platform, MindsEye.
Hello! Today we will be discussing many aspects of developing differentiable network layers in MindsEye as we explore the 2d convolution layer and its various implementations. First, for background, see my previous post about Test Driven Development with neural networks. Given these test facilities and perhaps more elemental layers, we need to construct a convolution layer that will work in large modern networks with large images as input.
Our first goal is to code a reference implementation, generally in pure java.
I’ve recently completed another large update to the MindsEye code, implementing a reference-counting base for many of the core classes. This memory management pattern provides us with much tighter system resource management and dramatically reduces load on JVM’s garbage collector. Memory contention has proven to be a main limiting factor in supporting modern large-scale deep-learning models, so these changes were quite beneficial and I think they suggest why Java has often been less popular in this field: The reliance on mark-sweep memory management in Java is often quite inefficient compared to other models when used on this problem.
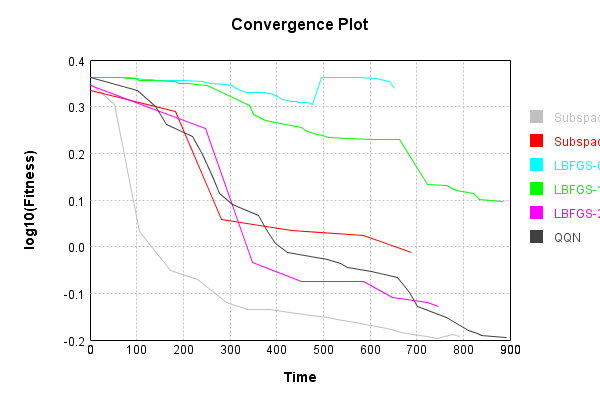
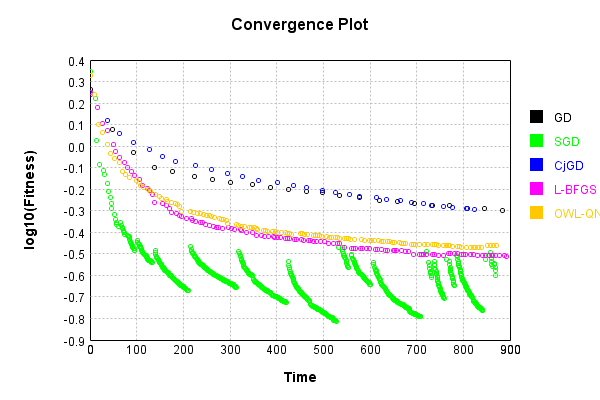
Now that I’ve cleaned up the testing and documentation of MindsEye, I have been able to re-focus on why I started writing it: Optimization Algorithm Research. In the course of playing with this code I have tried countless ideas, most of which taught me though failure instead of success… However I do have two ideas, fully implemented and demonstrated in MindsEye, that I’d like to introduce today: Recursive Subspace Optimization allows deep networks to be trained effectively, and Quadratic Quasi-Newton enhances L-BFGS with a quadratic term on the line-search path.
In the last article, we covered a common testing framework for individual components, but we didn’t cover how these networks are actually trained. More specifically, how should we design a test suite to cover something so broad as optimization? A big problem here is that the components are heavily dependent on each other and also vary greatly in function and contract, and so there are few opportunities for generic testing and validation logic.
A critical part of any good software is test code. It is an understatement that tests improve quality; they improve the scalability of the entire software development process. Tests let you write more code, faster code, better code. One of the leading testing methodologies is unit testing: the philosophy of breaking down software into individual components and testing each separately. It turns out that a great case study in unit test design also happens to be one of today’s hot tech topics - artificial neural networks.
One artificial intelligence tool that I’ve been playing with lately is an algorithm called word2vec. The basic idea is that words are given positions in high dimensional space, and the positions are optimized such that word distance indicates how often words are seen together. These numbers can then be used in a variety of ways, from a simple word similarity search to recurrent neural networks. In this article I will outline some uses of this amazing approach, along with links to sample code and results.
A recent project that has huge implications for the field of AI is NVidia’s CuDNN library and related cuda-based libraries. Beyond simply being very useful and enabling hardware accelerated AI with cutting-edge performance, it establishes a common layer of high-performance mathematical primitives that, while using the hardware to its best extent, provides a common api to write software. With my recent addition of CuDNN-based layers, Mindseye should behave comparably with any other state-of-the-art deep learning library.
Recent developments in MindsEye have yielded greatly increased speed and scalability of network training. Major improvements to the OpenCL kernels have increased speed in some tests by 50x or more, and data-parallel training has been tested with a Spark cluster. This combination of GPU and cluster computing support should bring MindsEye much closer to the performance and scale of other frameworks, if not in the competitive range! The componentization of the optimization code that I wrote about previously has enabled Spark support to be implemented in only about 100 lines in one self-contained class, a nice result of careful design.
Further research and development with MindsEye has produced two new features I would like to discuss today. The first is a working demonstration of a stacked sparse denoising image autoencoder, which is a fundamental tool in any deep learning toolkit. Second, I will introduce a useful tool for producing both static and interactive scientific reports, which I use to produce many of my demonstrations and conduct much of my research.